Hauptkomponenten-Analyse (HKA)
Die Hauptkomponenten-Analyse (HKA) ist eine der populärsten statistischen Methoden des Data-Minings. Führen Sie Ihre HKA in Excel unter Verwendung der XLSTAT Statistiksoftware durch.

Was ist eine Hauptkomponenten-Analyse?
Definition einer Hauptkomponenten-Analyse
Die Hauptkomponenten-Analyse (engl. Prinicipal Component Analysis, „PCA“) ist eine der am häufigsten verwendeten multivariaten Datenanalysemethoden, mit den man mehrdimensionale Datensätze mit quantitativen Variablen untersuchen kann. Sie wird häufig in der Biostatistik, im Marketing, in der Soziologie und in vielen anderen Bereichen eingesetzt.
Es handelt sich um eine Projektionsmethode, bei der Beobachtungen aus einem p-dimensionalen Raum mit p Variablen in einen k-dimensionalen Raum (mit k < p) projiziert werden, um ein Maximum an Informationen (die Information wird hier durch die Gesamtvarianz des Datensatzes gemessen) aus den ursprünglichen Dimensionen zu erhalten. Die Dimensionen der HKA werden auch Achsen oder Faktoren genannt. Wenn die mit den ersten zwei oder drei Achsen verbundenen Informationen einen ausreichenden Prozentsatz der Gesamtvariabilität des Streudiagramms ausmachen, können die Beobachtungen in einem zwei- oder dreidimensionalen Diagramm dargestellt werden, was die Interpretation erheblich erleichtert.
Die HKA kann somit als Data-Mining-Methode betrachtet werden, da man damit auf einfache Weise Informationen aus großen Datensätzen extrahieren kann. Es gibt mehrere Verwendungszwecke für diese Methode, darunter:
- Untersuchung und Visualisierung der Korrelationen zwischen den Variablen, um die Anzahl der anschließend zu messenden Variablen hoffentlich begrenzen zu können;
- Ermittlung von nicht korrelierten Faktoren, die lineare Kombinationen der Ausgangsvariablen sind, um diese Faktoren in Modellierungsverfahren wie der linearen Regression, der logistischen Regression oder der Diskriminanzanalyse zu verwenden.
- Visualisierung von Beobachtungen in einem 2- oder 3-dimensionalen Raum, um einheitliche oder atypische Gruppen von Beobachtungen zu identifizieren.
XLSTAT bietet ein komplettes und flexibles HKA-Feature, um Ihre Daten direkt in Excel zu untersuchen. XLSTAT bietet mehrere Standard- und fortgeschrittene Optionen an, die Ihnen einen tiefen Einblick in Ihre Daten ermöglichen.
Wie konfiguriert man eine Hauptkomponenten-Analyse in XLSTAT?
HKA auf Pearson oder Kovarianz
Die HKA wird zur Berechnung von Matrizen verwendet, um die Variablen in einen neuen Raum zu projizieren, indem eine neue Matrix verwendet wird, die den Grad der Ähnlichkeit zwischen den Variablen anzeigt. Es ist üblich, den Pearson-Korrelationskoeffizienten oder die Kovarianz als Ähnlichkeitsindex zu verwenden. Die Pearson-Korrelation und die Kovarianz haben den Vorteil, dass sie positive, halb definierte Matrizen ergeben, deren Eigenschaften in der HKA verwendet werden. Es können jedoch auch andere Indizes verwendet werden.
XLSTAT bietet mehrere Datenbehandlungen an, die auf den Eingabedaten vor den Berechnungen der Hauptkomponenten-Analyse angewendet werden können:
- Pearson, die klassische HKA, die die Daten vor den Berechnungen automatisch standardisiert oder normalisiert, um zu vermeiden, dass die Auswirkungen von Variablen mit hohen Varianzen auf das Ergebnis überhöht werden.
- Kovarianz, die mit nicht standardisierten Varianzen und Kovarianzen arbeitet (Variablen mit hohen Varianzen spielen bei den Ergebnissen eine größere Rolle).
- Spearman, entspricht einer klassischen HKA (auf der Grundlage der Pearson-Korrelation), die auf der Matrix der Ränge durchgeführt wird.
Traditionell wird eher ein Korrelationskoeffizient als die Kovarianz verwendet, da bei der Verwendung eines Korrelationskoeffizienten der Skaleneffekt wegfällt: Eine Variable, die zwischen 0 und 1 variiert, hat also bei der Projektion weniger Gewicht als eine Variable, die zwischen 0 und 1000 variiert. In bestimmten Bereichen wird die Kovarianz jedoch verwendet, wenn die Variablen auf einer identischen Skala liegen sollen oder wenn die Varianz der Variablen die Faktorenbildung beeinflussen soll.
Steht nur eine Ähnlichkeitsmatrix und keine Tabelle mit Beobachtungen/Variablen zur Verfügung, oder soll ein anderer Ähnlichkeitsindex verwendet werden, kann eine HKA ausgehend von der Ähnlichkeitsmatrix (Korrelation oder Kovarianz) durchgeführt werden.
HKA mit zusätzlichen Variablen und Beobachtungen
XLSTAT erlaubt das Hinzufügen von (qualitativen oder quantitativen) Variablen oder Beobachtungen zur HKA, nachdem diese berechnet wurde. Diese Variablen oder Beobachtungen werden als ergänzend bezeichnet. Dies kann in verschiedenen Kontexten verwendet werden. Hier sind zwei Beispiele:
- Wenn der Benutzer grob untersuchen möchte, wie eine Gruppe von abhängigen Variablen mit den anderen zusammenhängt. Die abhängigen Variablen sollten in diesem Fall als ergänzende Variablen verwendet werden, während die anderen (d. h. die unabhängigen Variablen) zur Erstellung der HKA herangezogen werden sollten.
- Wenn der Benutzer einfach nur sehen möchte, wie sich verschiedene Kategorien von Beobachtungen im HKA-Raum verhalten (z. B. Männer gegenüber Frauen). In diesem Fall kann eine qualitative Zusatzvariable (Geschlecht) verwendet werden, um die Beobachtungen nach dem Geschlecht, zu dem sie gehören, einzufärben. Es ist auch möglich, die Mittelpunkte der Kategorien sowie Konfidenzellipsen, um die Kategorien herum anzuzeigen.
HKA mit Rotationen: Varimax und andere
Rotationen können auf die Faktoren angewendet werden. Es stehen mehrere Methoden zur Verfügung, darunter Varimax, Quartimax, Equamax, Parsimax, Quartimin und Oblimin und Promax.
Was sind die Ergebnisse der Hauptkomponentenanalyse in XLSTAT?
Das XLSTAT HKA-Feature liefert Ergebnisse bezüglich den Variablen und den Beobachtungen.
Deskriptive Statistik: Die Tabelle der deskriptiven Statistiken zeigt die einfachen Statistiken für alle ausgewählten Variablen. Dies beinhaltet die Anzahl der Beobachtungen, die Anzahl der fehlenden Werte, die Anzahl der nicht fehlenden Werte, den Mittelwert und die Standardabweichung (unverzerrt).
Korrelations-/Kovarianzmatrix: Diese Tabelle zeigt die Daten, die später für die Berechnungen verwendet werden. Die Art der Korrelation hängt von der auf der Registerkarte »Allgemein« im Dialogfeld gewählten Option ab. Bei Korrelationen werden signifikante Korrelationen fett dargestellt.
Bartlett's Sphärizitätstest: Die Ergebnisse des Sphärizitätstests nach Bartlett werden angezeigt. Sie werden verwendet, um die Hypothese zu bestätigen oder abzulehnen, dass die Variablen nicht signifikant miteinander korrelieren.
Maß für die Stichprobenadäquanz von Kaiser-Meyer-Olkin: Diese Tabelle gibt den Wert des KMO-Maßes für jede einzelne Variable und das gesamte KMO-Maß an. Das KMO-Maß liegt zwischen 0 und 1. Ein niedriger Wert entspricht dem Fall, dass es nicht möglich ist, synthetische Faktoren (oder latente Variablen) zu extrahieren. Mit anderen Worten: Die Beobachtungen ergeben nicht das Modell, das man sich vorstellen könnte (die Stichprobe ist »unzureichend«). Kaiser (1974) empfiehlt, ein Faktormodell nicht zu akzeptieren, wenn die KMO weniger als 0,5 beträgt. Liegt die KMO zwischen 0,5 und 0,7, ist die Qualität der Stichprobe mittelmäßig, bei einer KMO zwischen 0,7 und 0,8 ist sie gut, zwischen 0,8 und 0,9 sehr gut und darüber hinaus ausgezeichnet.
Eigenwerte: Es werden die Eigenwerte und das entsprechende Diagramm (Scree Plot) angezeigt. Die Anzahl der Eigenwerte ist gleich der Anzahl der Nicht-Null-Eigenwerte.
Wenn die entsprechenden Ausgabeoptionen aktiviert sind, zeigt XLSTAT anschließend die Faktorladungen im neuen Raum an, dann die Korrelationen zwischen den Ausgangsvariablen und den Komponenten im neuen Raum. Die Korrelationen sind gleich den Faktorladungen in einer normalisierten HKA (auf der Korrelationsmatrix).
Wenn zusätzliche Variablen ausgewählt wurden, werden die entsprechenden Koordinaten und Korrelationen am Ende der Tabelle angezeigt.
Anschließend werden die Faktorenscores im neuen Raum angezeigt. Wenn zusätzliche Daten ausgewählt wurden, werden diese am Ende der Tabelle angezeigt.
Beiträge: Diese Tabelle zeigt die Beiträge der Beobachtungen zur Bildung der Hauptkomponenten.
Kosinusquadrate: In dieser Tabelle werden die quadrierten Kosinus zwischen den Beobachtungsvektoren und den Faktorachsen angezeigt.
Wenn eine Rotation angefordert wurde, werden die Ergebnisse der Rotation angezeigt, wobei die Rotationsmatrix zuerst auf die Faktorladungen angewendet wird. Danach folgen die modifizierten Variabilitätsprozentsätze, die mit jeder der an der Rotation beteiligten Achsen verbunden sind. Die Koordinaten, Beiträge und Kosinus der Variablen und Beobachtungen nach der Rotation werden in den folgenden Tabellen angezeigt.
Welche Diagramme werden für die Hauptkomponenten-Analyse in XLSTAT angezeigt?
Einer der Vorteile der Hauptkomponentenanalyse besteht darin, dass sie sowohl eine optimale Visualisierung der Variablen und Daten als auch Biplots liefert, die beide miteinander kombinieren (siehe unten). Diese Darstellungen sind jedoch nur dann zuverlässig, wenn die Summe der Prozentsätze der mit den Achsen des Darstellungsraums verbundenen Variabilität hoch genug ist. Wenn dieser Prozentsatz hoch ist (z. B. 80%), kann man davon ausgehen, dass die Darstellung zuverlässig ist. Ist der Prozentsatz niedrig, empfehlen wir, Darstellungen auf mehreren Achsenpaaren vorzunehmen, um die auf den ersten beiden faktoriellen Achsen vorgenommene Interpretation zu validieren.
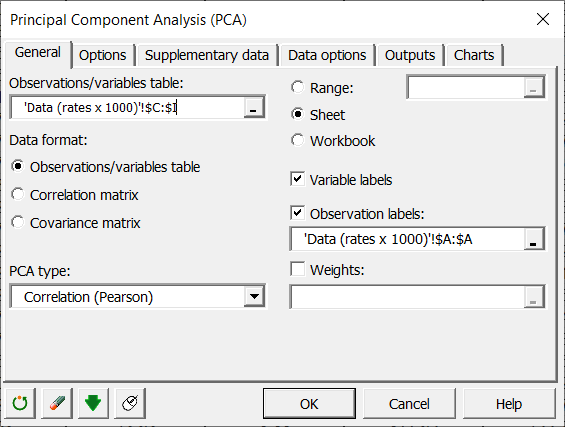
Der HKA-Korrelationskreis oder das Variablendiagramm
Der Korrelationskreis (oder das Variablendiagramm) zeigt die Korrelationen zwischen den Komponenten und den Ausgangsvariablen an. Ergänzende Variablen können auch in Form von Vektoren dargestellt werden.
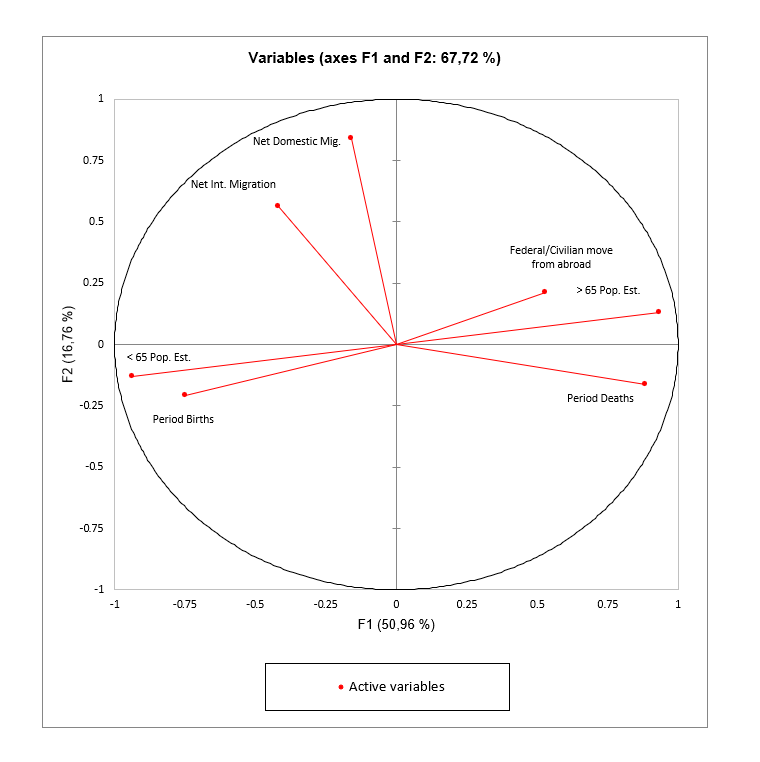
Die HKA-Beobachtungsdiagramme
Die Beobachtungsdiagramme stellen die Beobachtungen im HKA-Raum dar.
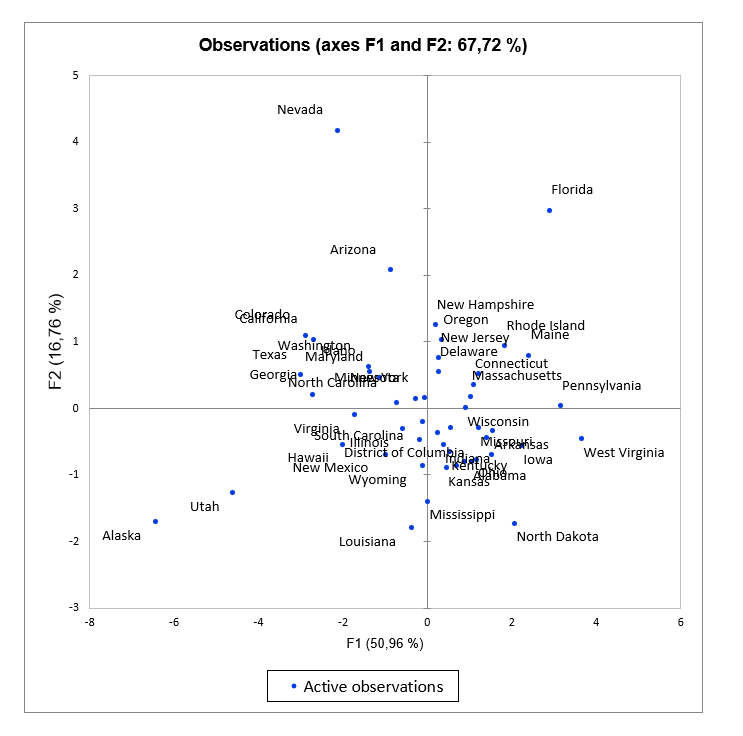
Die HKA-Biplots
Die Biplots stellen die Beobachtungen und Variablen gleichzeitig im neuen Raum dar. Auch hier können die zusätzlichen Variablen in Form von Vektoren aufgetragen werden. Es gibt verschiedene Arten von Biplots:
- Korrelations-Biplot: Diese Art von Biplot ermöglicht es, die Winkel zwischen den Variablen zu interpretieren, da sie direkt mit den Korrelationen zwischen den Variablen verbunden sind. Die Position von zwei Beobachtungen, die auf einen Variablenvektor projiziert werden, lässt Rückschlüsse auf ihr relatives Niveau auf derselben Variablen zu. Der Abstand zwischen zwei Beobachtungen ist eine Annäherung an den Mahalanobis-Abstand im Raum der k Faktoren. Schließlich ist die Projektion eines Variablenvektors in den Repräsentationsraum eine Annäherung an die Standardabweichung der Variablen (die Länge des Vektors im Raum der k Faktoren ist gleich der Standardabweichung der Variablen).
- Abstands-Biplot: Ein Abstands-Biplot ermöglicht die Interpretation der Abstände zwischen Beobachtungen, da sie eine Annäherung an ihren euklidischen Abstand im Raum der p Variablen darstellen. Die Position von zwei Beobachtungen, die auf einen Variablenvektor projiziert werden, lässt Rückschlüsse auf ihr relatives Niveau auf dieser Variablen zu. Schließlich ist die Länge eines Variablenvektors im Repräsentationsraum repräsentativ für die Höhe des Beitrags der Variablen zur Konstruktion dieses Raums (die Länge des Vektors ist die Quadratwurzel aus der Summe der Beiträge).
- Symmetrisches Biplot: Dieses von Jobson (1992) vorgeschlagene Biplot liegt zwischen den beiden vorhergehenden Biplots. Wenn weder die Winkel noch die Abstände interpretiert werden können, kann diese Darstellung gewählt werden, da sie einen Kompromiss zwischen den beiden darstellt.
XLSTAT erlaubt es, den Koeffizienten zu wählen, dessen Quadratwurzel mit den Koordinaten der Variablen multipliziert wird. Dieser Koeffizient erlaubt es, die Position der Punkte der Variablen im Biplot anzupassen, um ihn besser lesbar zu machen. Wenn er auf einen anderen Wert als 1 gesetzt wird, kann die Länge der Variablenvektoren nicht mehr als Standardabweichung (Korrelations-Biplot) oder Beitrag (Distanz-Biplot) interpretiert werden.
Tutorien zur Durchführung von HKA in Excel unter Verwendung von XLSTAT
Mehrere Beispiele und Anwendungen sind auf unserer Webseite verfügbar, die Ihnen helfen werden, eine Hauptkomponenten-Analyse nach Ihren Bedürfnissen zu erstellen und zu interpretieren.
- Beispiel für die Durchführung einer Hauptkomponenten-Analyse(HKA), engl. Prinicipal Component Analysis, „PCA“).
- Beispiel für die Durchführung einer Hauptkomponenten-Analyse(HKA) mit zusätzlichen Variablen und Personen.
- Beispiel für die Anpassung eines Diagramms der Hauptkomponenten-Analyse(HKA) für eine einfachere Interpretation.
- Beispiel für die Verwendung der Hauptkomponenten-Analyse und die Anwendung von Filtern auf der Grundlage von Kommunalitäten (Kosinusquadrate).


analysieren sie ihre daten mit xlstat
Verwandte Funktionen