XLSTAT version 2022.1 - Data Mining
XLSTAT 2022.1 vous offre de nouvelles possibilités pour l'analyse exploratoire des données et le regroupement, quel que soit votre domaine.
Découvrez toutes les nouveautés !
Analyse des Correspondances Détendancée (ACD)
Qu’est-ce que l’Analyse Factorielle des Correspondances ?
Il s’agit d’une approche de l'analyse factorielle des correspondances qui vous permet d'étudier l'association entre deux variables qualitatives dans certains cas et qui a été proposée par Hill et Gauch (1980).
Quand peut-on l'utiliser ?
Cette technique populaire d’analyse multivariée est largement utilisée pour explorer les matrices de données potentiellement creuses en écologie. Son but est de corriger les deux freins de l’analyse des correspondances classique : l’effet “fer à cheval” et la compression des distances entre les points se trouvant aux extrémités des axes.
Les nouveautés dans XLSTAT sur l'Analyse Factorielle des Correspondances
- Vous pouvez désormais lancer l’ACD depuis l’onglet Options de la boîte de dialogue de l'Analyse Factorielle des Correspondances. Il suffit d’entrer les paramètres utiles aux calculs, à savoir le nombre de segments pour découper les axes et le nombre de remises à l'échelle à effectuer. Par défaut, le nombre de segments est fixé à 26 et le nombre de remises à l'échelle est fixé à 4.
- Rotation : Il est également possible d’appliquer une rotation à l’une des matrices des coordonnées principales, en utilisant les méthodes Quartimin ou Varimax.
Accessible depuis le menu Analyse des données (toutes solutions de XLSTAT)
Analyse Discriminante des Composantes Principales
Qu'est-ce que l’analyse discriminante des composantes principales ?
L’analyse discriminante des composantes principales vise à identifier et décrire des classes d’individus.
Quand peut-on l'utiliser ?
Cette nouvelle fonctionnalité de XLSTAT-R a été développée spécifiquement pour les populations génétiquement structurées. Nous avons un exemple de tutoriel qui décrit des clusters d’individus selon le nombre d’allèles différents présents dans leurs loci.
Accessible depuis le menu XLSTAT-R (toutes solutions sauf XLSTAT Basic)
Classification k-means
Qu'est-ce que la classification k-means ?
La classification k-means est un algorithme d’apprentissage non supervisé qui a pour but de résoudre des problèmes de classification. Il présente plusieurs avantages, tels que :
- Un objet peut être affecté à une classe au cours d'une itération puis changer de classe à l'itération suivante, ce qui est impossible avec la classification ascendante hiérarchique (CAH).
- Elle permet d’explorer plusieurs solutions possibles.
L'inconvénient de cette méthode est qu’elle ne permet pas d'identifier facilement le nombre optimal de classes. Les méthodes k-means et CAH sont donc complémentaires.
Quand peut-on l'utiliser ?
Cette technique populaire d’analyse des données exploratoire peut être utilisée pour la segmentation des clients, la détection de fraude en assurance, la classification des documents, la segmentation des images et bien d’autres applications.
Vous pouvez regarder ce tutoriel où nous avons cherché à créer des classes homogènes d'États à partir de données démographiques.
Les nouveautés dans XLSTAT sur la classification k-means
- Deux indices de dissimilarité supplémentaires sont désormais disponibles (onglet général). La distance de cosine est recommandée pour l'analyse de données textuelles tandis que la distance de Jaccard est recommandée pour les jeux de données qui nécessitent une analyse plus poussée.
- Dans le champ Partition de départ de l'onglet options, nous avons ajouté les algorithmes K++ et K||. Ils permettent de définir la façon dont les objets sont assignés aux classes dans la première itération de l'algorithme de clustering.
- Un onglet de prédiction a été ajouté afin d'identifier la classe d'une nouvelle observation.
- Des scores de silhouettes ont été ajoutés aux sorties. Ces scores vous aideront à calculer la qualité de l'algorithme de clustering.
Accessible depuis le menu Machine Learning (toutes solutions sauf XLSTAT Basic)
Partitionnement univarié
Qu'est-ce que le partitionnement univarié ?
Le partitionnement univarié est une technique de data mining qui a pour but de grouper les individus/objets en se basant sur une seule variable.
Quand peut-on l'utiliser ?
Par exemple, vous pouvez utiliser le partitionnement univarié en analyse sensorielle pour réaliser des groupes de consommateurs en se basant sur leur évaluation d’un produit. Vous pouvez également regrouper des villes selon leur taux de précipitation annuel, regrouper les athlètes selon leurs performances, créer des groupes de clients selon leur tranche d’âge, etc.
N’hésitez pas à lire notre exemple qui sépare une classe d’élèves en groupes de travail différents dans chaque matière selon leurs notes !
Les nouveautés dans XLSTAT sur le partitionnement univarié
L’algorithme de XLSTAT pour le partitionnement univarié a été optimisé. Les calculs sont plus rapides et plus précis. Plusieurs bugs ont été réglés.
Accessible depuis le menu Analyse des données (toutes solutions de XLSTAT)
Imputation de données manquantes
Qu'est-ce que l’imputation de données manquantes ?
Les méthodes d’imputation vous permettent de compléter ou de nettoyer votre jeu de données avant de lancer une analyse. Des méthodes différentes sont disponibles dans l’outil “Données manquantes” de XLSTAT.
Quand peut-on l'utiliser ?
Par exemple, dans les sondages, il nous arrive d’avoir des réponses vides ou des valeurs comme “NA” ou “99” car les sondés peuvent sauter des questions. Ce type de valeur doit être retiré ou imputé selon le type de variable et le but de la modélisation.
Les nouveautés dans XLSTAT sur l'imputation de données manquantes
Dans cette version, nous avons ajouté une nouvelle option dans la boîte de dialogue Données manquantes qui vous aidera à mieux comprendre les différents patterns d'absence de données. Une analyse des correspondances multiples (ACM) est réalisée pour cet objectif. Dans la feuille des sorties, une carte factorielle est affichée pour illustrer les liens entre les variables avec des données manquantes et sans données manquantes.
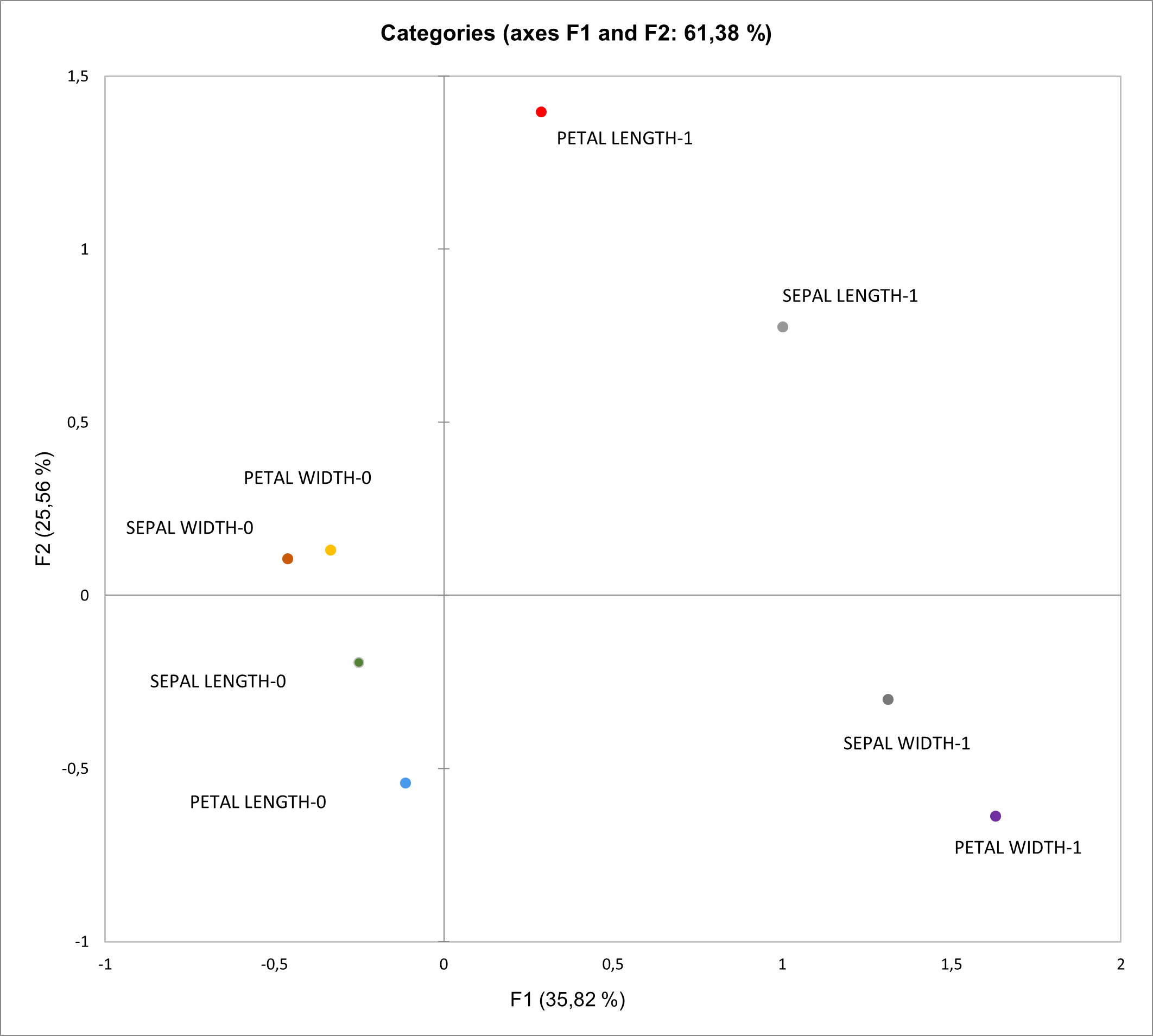
Accessible depuis le menu Préparation des données (toutes solutions de XLSTAT)
Comment obtenir XLSTAT 2022.1 ?
Si vous avez la version d'essai ou si vous utilisez une licence valide, vous pouvez télécharger ci-dessous la version appropriée.
Derniers tweets
Pas de tweet à afficher